
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 코사인
- 비동기처리
- redissearch
- 레디스스트림
- god object
- 장애복구
- DLT
- 배치처리
- 마케팅 #퍼플카우 #새스고딘 #혁신 #독서 #이북
- 메세지브로커
- 자연어캐싱
- jedis
- 레디스
- 시맨틱캐싱
- OOP
- SaaS
- redisstreams
- aof
- springboot
- blockingqueue
- 메시지브로커
- retry
- 임베딩
- 백엔드
- Kafka
- 객체지향적사고
- rdb
- redis
- 테스트코드
- 데이터유실방지
- Today
- Total
pandaterry's 개발로그
혼자서도 잘해요: 메세지 브로커 없이도 살아남은 Logging System 구조 이야기 본문

운영 중 발생한 장애를 원인부터 끝까지 추적하려면, 신뢰할 수 있는 로그가 반드시 필요합니다.
특히 JPA를 사용하는 시스템에서는, 엔티티가 변경될 때마다 무엇이 바뀌었고, 누가 변경했으며, 언제 어떤 요청에서 발생했는지 그 이력을 상세히 남기는 일이 중요합니다.
많은 시스템에서는 Kafka나 Redis Stream, 또는 Change Data Capture 기반 구조를 활용합니다.
하지만 다음과 같은 환경에서는 그런 선택이 불가능합니다.
- 외부망과 완전히 단절된 폐쇄망 환경 (군/금융기관 등)
- Kafka, Redis, ELK 등 인프라 설치 자체가 제한된 경우
- 외부 브로커 없이도 로그 유실 없는 처리가 요구되는 상황
실제로 제가 경험한 한 시스템은 배치 업로드 한 번에 수만 건 이상의 엔티티가 변경되는 구조였습니다.
이때 Kafka 없이도 로그를 안정적으로 쌓아야 하는 요구가 있었고, 단순한 AOP나 JPA Auditing만으로는 변경 필드 단위의 추적이나 운영 종료 시 flush 보장 같은 요구를 만족할 수 없었습니다.
그래서 시작했습니다.
“외부 인프라 없이도 운영 가능한, 고신뢰의 비동기 변경 로그 시스템”
이 글에서는 Hibernate의 EventListener를 활용하여 멀티스레드 환경에서 안정적으로 엔티티 변경사항을 감지하고,
JDBC batch insert로 빠르게 디스크에 저장하는 구조를 설계하고 검증한 흐름을 공유드리고자 합니다.
- 실제 TPS 500 이상의 부하 환경에서도 평균 응답 지연은 5ms 이하
- 배치 insert 적용으로 JVM 힙 사용량 70MB 수준으로 유지
- 유실된 로그 0건
- 별도 모니터링 도구 없이도 Prometheus 기반 지표 수집 가능
구조는 단순하지만, 운영 종료 시 flush 보장, shutdown hook 등의 안정성을 갖췄으며
향후에는 LMAX Disruptor와 같은 lock-free 구조로 확장 가능한 기반도 포함하고 있습니다.
전역 엔티티 리스너 설정
: 여기서 엔티티들의 변화를 감지합니다.
public class EntityChangeListener
implements PostUpdateEventListener, PostDeleteEventListener, PostInsertEventListener {
private final LoggingStrategy loggingStrategy;
private final EntityLoggingProperties loggingProperties;
private final EntityStateCopier stateCopier;
private final Logger log = LoggerFactory.getLogger(EntityChangeListener.class);
@Override
public void onPostInsert(PostInsertEvent event) {
if (loggingProperties.shouldLogChanges(event.getEntity())) {
loggingStrategy.logChange(null, event.getEntity(), Operation.CREATE);
}
}
@Override
public void onPostUpdate(PostUpdateEvent event) {
if (loggingProperties.shouldLogChanges(event.getEntity())) {
Object oldEntity = stateCopier.cloneEntity(event);
loggingStrategy.logChange(oldEntity, event.getEntity(), Operation.UPDATE);
}
}
@Override
public void onPostDelete(PostDeleteEvent event) {
if (loggingProperties.shouldLogChanges(event.getEntity())) {
loggingStrategy.logChange(event.getEntity(), null, Operation.DELETE);
}
}
@Override
public boolean requiresPostCommitHandling(EntityPersister persister) {
return false;
}
}
BlockingQueue 로그 엔티티 처리기
: 여러 스레드로부터 들어오는 엔티티의 변화를 이 클래스에서 동시성 문제가 없게 처리합니다.
public class BlockingQueueLoggingStrategy implements LoggingStrategy {
private final LogEntryRepository logEntryRepository;
private final EntityLoggingProperties loggingProperties;
private final LogEntryFactory logEntryFactory;
private final ObjectMapper objectMapper;
private final LogStorage logStorage;
private final MicrometerLogMetricsRecorder metrics;
private BlockingQueue<LogEntry> logQueue;
private ExecutorService logProcessorPool;
public BlockingQueueLoggingStrategy(LogEntryRepository logEntryRepository,
EntityLoggingProperties loggingProperties,
LogEntryFactory logEntryFactory,
LogStorage logStorage,
ObjectMapper objectMapper,
MicrometerLogMetricsRecorder metrics) {
this.logEntryRepository = logEntryRepository;
this.loggingProperties = loggingProperties;
this.logEntryFactory = logEntryFactory;
this.metrics = metrics;
this.logStorage = logStorage;
this.objectMapper = objectMapper;
this.objectMapper.enable(SerializationFeature.INDENT_OUTPUT);
}
@PostConstruct
public void init() throws IOException {
logStorage.init();
this.logQueue = new LinkedBlockingQueue<>(loggingProperties.getStrategy().getQueueSize());
this.logProcessorPool = Executors.newFixedThreadPool(loggingProperties.getStrategy().getThreadPoolSize());
for (int i = 0; i < loggingProperties.getStrategy().getThreadPoolSize(); i++) {
logProcessorPool.submit(this::processLogs);
}
Runtime.getRuntime().addShutdownHook(new Thread(this::shutdown));
}
@Override
public void logChange(Object oldEntity, Object newEntity, Operation operation) {
if (!loggingProperties.shouldLogChanges(oldEntity != null ? oldEntity : newEntity)) {
return;
}
LogEntry entry = logEntryFactory.create(oldEntity, newEntity, operation);
try {
logStorage.write(entry);
} catch (IOException e) {
throw new RuntimeException(e);
}
offerToQueue(entry);
}
private void offerToQueue(LogEntry entry) {
long startNanos = System.nanoTime();
long tookNanos = System.nanoTime() - startNanos;
if (logQueue.remainingCapacity() == 0)
return;
boolean offered = logQueue.offer(entry);
metrics.recordOfferLatency(tookNanos);
if (!offered) {
metrics.incrementDroppedCount();
}
metrics.gaugeQueueSize(logQueue.size());
}
/**
* 배치를 저장시 batchUpdate에서 안하는 이유
* : 스케쥴러로 동시에 배치업로드하는 방식이라 그럼. 배치를 repository 레이어에서 관리하는 순간 스케쥴러에서 관리가 어려워짐.
*/
private void processLogs() {
int batchSize = loggingProperties.getJpaBatchSize();
try {
while (!Thread.currentThread().isInterrupted()) {
while (logQueue.size() < batchSize) { // 배치사이즈에 도달하지 않으면 flush 스케쥴러에서 drainsTo 하기전에 미리 처리해줌.
Thread.sleep(50);
}
List<LogEntry> batch = new ArrayList<>(batchSize);
// 동시성을 고려하여 batch.add 가 아닌 큐에서 바로 drainsTo 를 사용함.
int drained = logQueue.drainTo(batch, batchSize);
if (drained > 0) {
saveBatch(batch);
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
private void saveBatch(List<LogEntry> toSave) {
int success = 0;
int batchCount = loggingProperties.getJpaBatchSize();
long startNanos = System.nanoTime();
try {
logEntryRepository.saveBatch(toSave);
success++;
} catch (Exception e) {
metrics.incrementSaveErrorCount();
}
long tookNanos = System.nanoTime() - startNanos;
metrics.recordBatchSize(batchCount);
metrics.recordBatchLatency(tookNanos);
metrics.incrementProcessedCount(success);
metrics.gaugeQueueSize(logQueue.size());
}
// 배치사이즈까지 안모으고 바로 플러시
@Scheduled(fixedDelayString = "${logging.strategy.flush-interval:5000}")
@Override
public int flush() {
int batchSize = loggingProperties.getJpaBatchSize();
List<LogEntry> batch = new ArrayList<>(batchSize);
int drained = logQueue.drainTo(batch, batchSize);
if (drained > 0) {
// 플러시 지연 측정
long start = System.nanoTime();
saveBatch(batch);
long took = System.nanoTime() - start;
metrics.recordFlushLatency(took);
}
// (선택) 큐 사이즈 계측
metrics.gaugeQueueSize(logQueue.size());
return drained;
}
@Override
public void shutdown() {
logProcessorPool.shutdown();
try {
if (!logProcessorPool.awaitTermination(10, TimeUnit.SECONDS)) {
logProcessorPool.shutdownNow();
}
} catch (InterruptedException e) {
logProcessorPool.shutdownNow();
}
int flushed = flush();
logStorage.close();
metrics.incrementShutdownFlushedCount(flushed);
}
}
JDBC 배치 인서트 처리
: 참고로 배치 개수 분할 처리는 스케쥴러도 동시에 사용해야하기 때문에 다른 클래스에서 담당합니다. 이 클래스에선 오직 batch 메서드를 호출하여 여러건을 단건으로 만드는 역할만 합니다.
public class LogEntryRepository {
private final JdbcTemplate jdbcTemplate;
private final ObjectMapper objectMapper;
@Transactional
public void saveBatch(List<LogEntry> toSave) {
if (toSave == null || toSave.isEmpty()) {
log.warn("저장할 로그 엔트리가 없습니다.");
return;
}
String sql = """
INSERT INTO log_entries (id, entity_name, entity_id, operation, changes, created_at)
VALUES (?::uuid, ?, ?, ?, ?::jsonb, ?)
""";
List<Object[]> batchArgs = toSave.stream()
.map(this::convertToObjectArray)
.filter(Objects::nonNull)
.collect(Collectors.toList());
if (!batchArgs.isEmpty()) {
try {
int[] results = jdbcTemplate.batchUpdate(sql, batchArgs);
log.info("배치 저장 완료: {} 건", results.length);
// 실패한 건수 체크
long failedCount = java.util.Arrays.stream(results)
.filter(result -> result == PreparedStatement.EXECUTE_FAILED)
.count();
if (failedCount > 0) {
log.warn("배치 처리 중 실패한 건수: {}", failedCount);
}
} catch (Exception e) {
log.error("배치 저장 실패", e);
throw new RuntimeException("로그 엔트리 배치 저장 실패", e);
}
}
}부하테스트 환경
- K6 부하테스트 툴 사용
- 총 20분동안 Insert, Update로 3가지 엔티티에 대해 변화를 주며 테스트
- 테스트 후 확인결과, 총 26만건 이상의 로그가 실패없이 생성.
부하테스트(k6) 결과
테스트 개요
- 총 요청 수: 274,728회
- 테스트 시간: 약 2분(Iteration_rate ≈ 13.1반복/초)
- 가상 사용자(VUs): 최대 38명(설정 상 최대 100명)
데이터 전송량
- 수신된 데이터: 약 73.4 MB (73,432,426 bytes) → 초당 약 84 KB/s
- 전송된 데이터: 약 49.3 MB (49,270,316 bytes) → 초당 약 56 KB/s
응답 시간(latency)
- 평균 HTTP 요청 지연: 4.15 ms
- 중앙값(median): 2.91 ms
- 90th percentile: 5.12 ms
- 95th percentile: 8.23 ms
- 최대 지연: 179.26 ms
- 연결(connecting) 시간 평균: 0.002 ms (최대 28.6 ms)
- 요청 전송(sending) 평균: 0.016 ms
- 서버 응답 대기(waiting) 평균: 4.05 ms
- 응답 수신(receiving) 평균: 0.08 ms
Prometheus + Grafana 로 로그 처리 지표 수집
단건 Insert vs JDBC Batch Insert(1000건)
: 기본적으로 5초에 한번씩 스케쥴러로 flush하는 건 유지했습니다.

- 단건 Insert : G1 Eden Space 힙 메모리 사용률이 최대 300MB 도달, G1 Old Gen은 별로 사용하질 않아서 40~50MB 정도 입니다.
- JDBC Batch Insert : G1 Eden Space 힙 메모리 사용률이 최대 30MB 도달, G1 Old Gen은 비슷하게 40~50MB 유지
Batch Insert 로 평균 JVM 힙메모리 180MB -> 70MB로 2.5배 효율화
Drop - 유실(큐에 들어가지 못하고 유실된 로그) 건수(0건)

부하테스트동안 한건의 유실된 로그가 없었습니다.
스루풋 - 초당 처리된 배치(1,000건) 개수
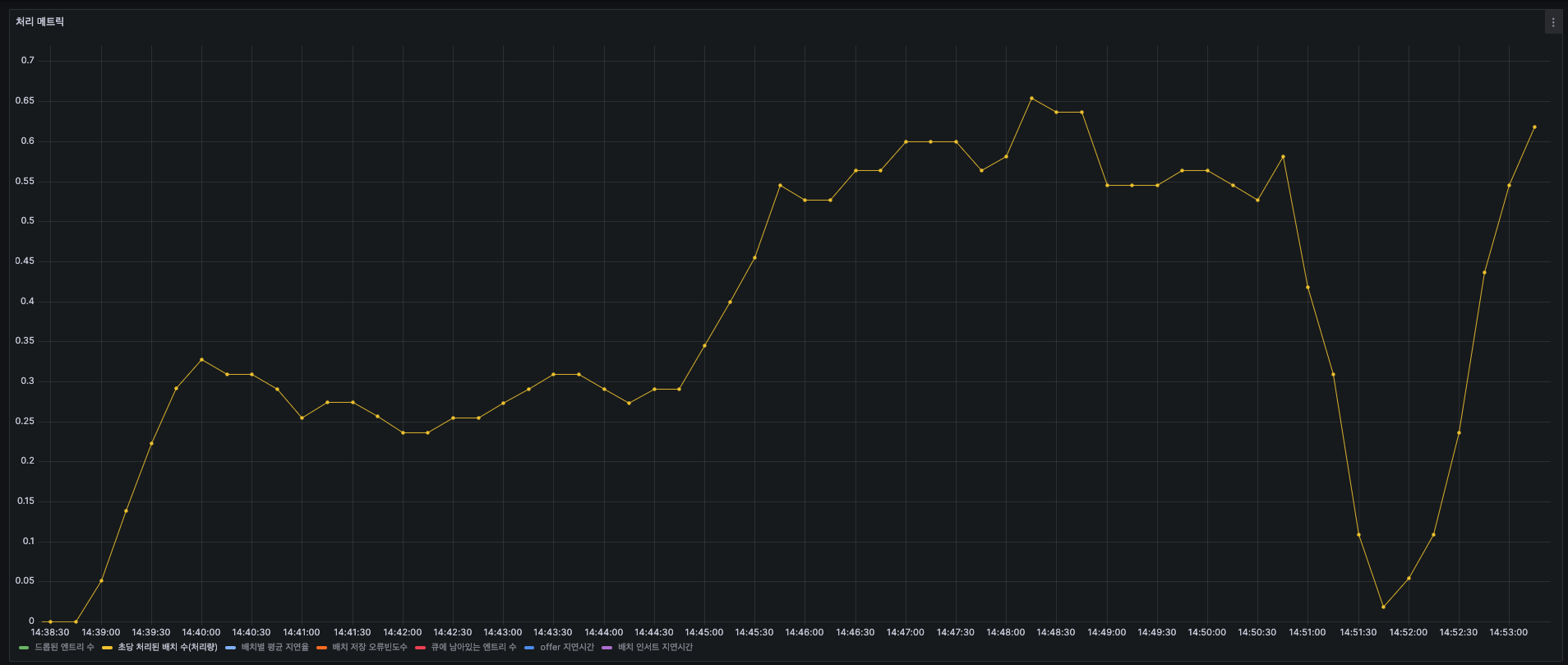
- 초반에 0에서 300건(0.3) 로그 처리하고, 점점 올라가면서 피크에서 655건(0.655) 처리를 합니다.
- 그러다가 다시 0건에 가깝게 내려가는데 이건 k6테스트 특성상 동시성 처리에서 테스트상 잠깐 멈춘 것으로 보입니다.
- 결론적으로 평균적으로 초당 4~500건의 로그를 처리합니다.
평균 처리량 : 초당 400~500건
최대 처리량 : 초당 655건
Latency - 배치별 평균 지연율
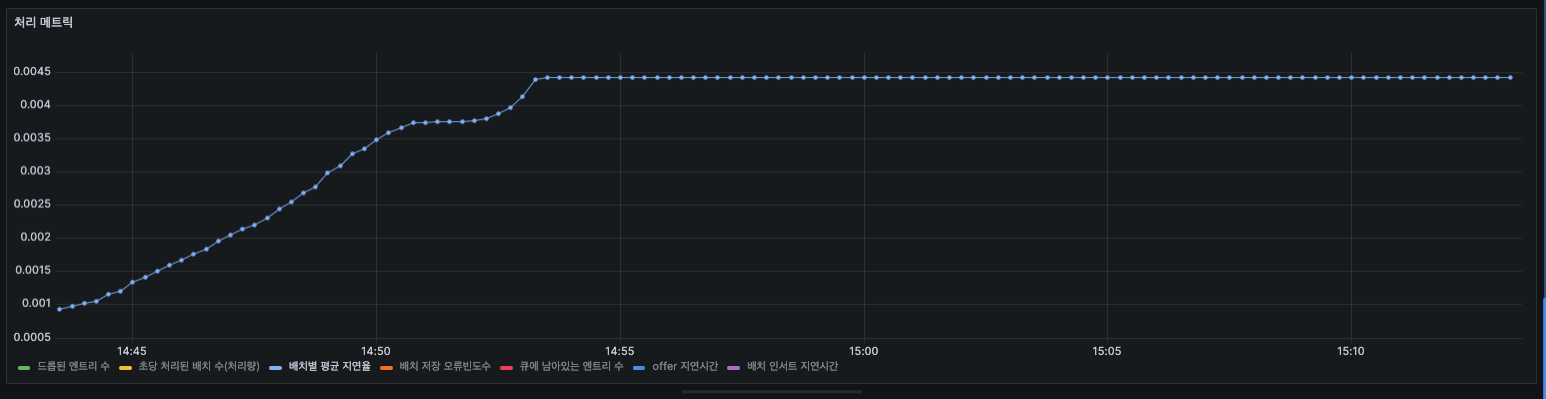
- 계속 오르다가 0.00442에 머무는 걸 볼 수 있습니다. 거의 지연이 없습니다.
Error - 배치 저장시 발생한 오류의 빈도수(0건)
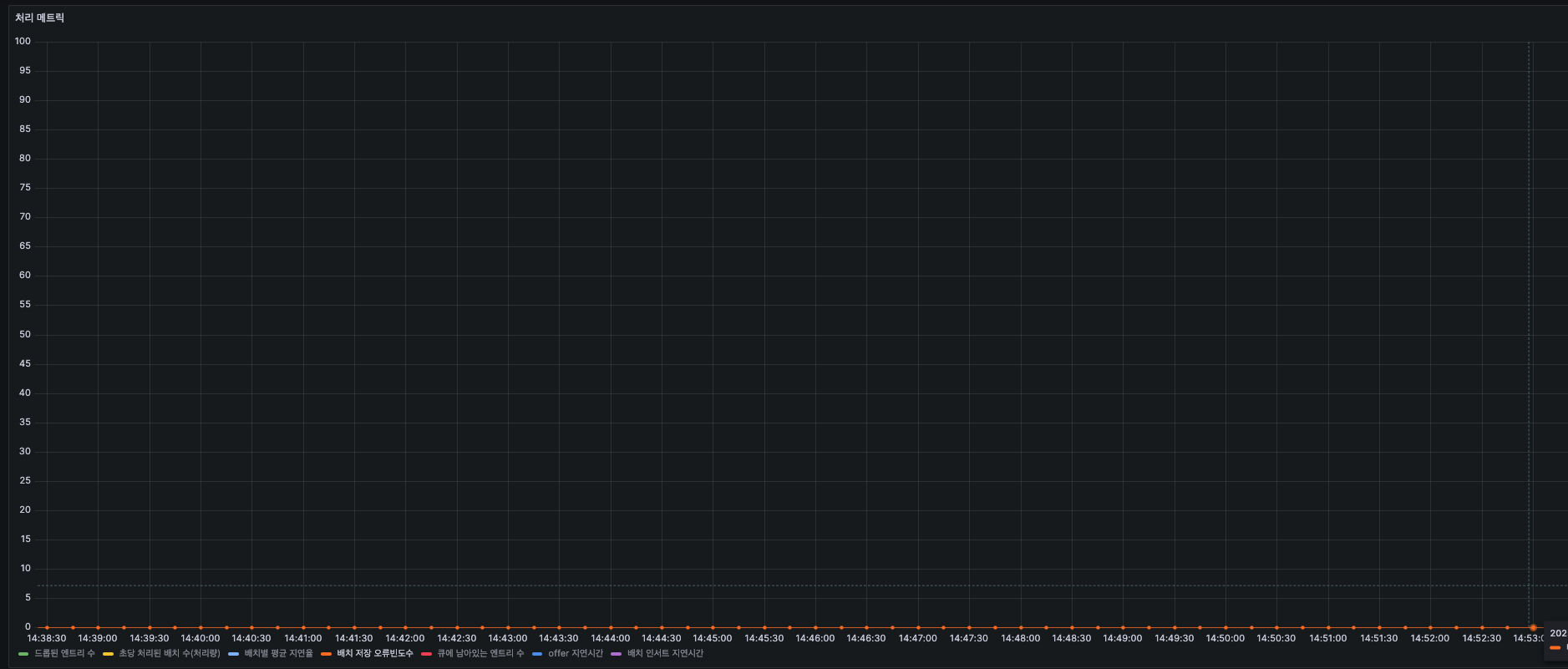
부하테스트동안 한건의 오류도 없었습니다.
Queue - 큐에 남아있는 로그 수(배치 사이즈 : 1000, 큐 사이즈 : 10만)
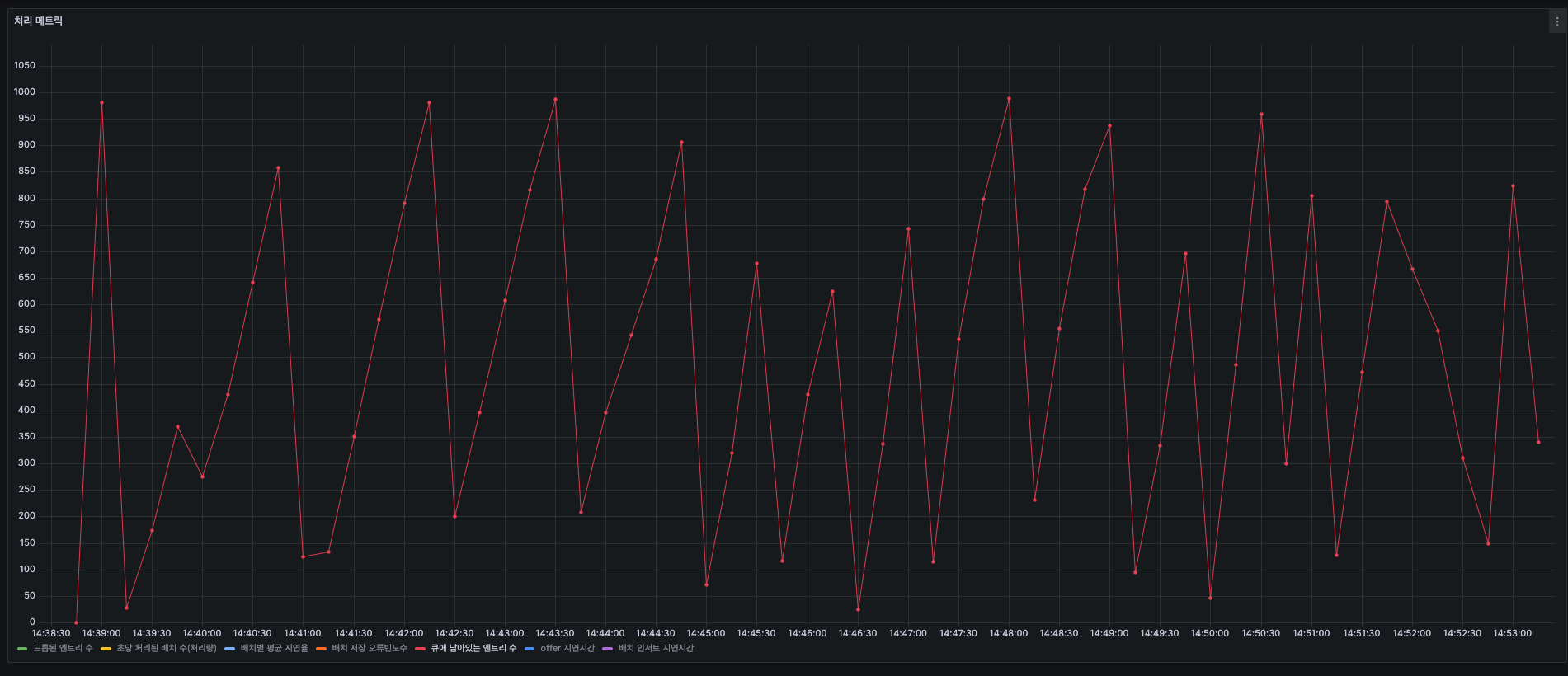
- 초반에는 배치 사이즈인 1,000까지 치솟았다가 인서트를 하고 초기화되며 왔다갔다를 반복합니다.
- 같은 주기로 작동하지 않는 이유는 스케쥴러가 5초단위로 큐에 있는 데이터를 처리하기 때문입니다.
참고로, 스케쥴러는 배치 인서트 전에 로그를 저장함으로서 로그 확인의 사용성을 높이기 위한 목적으로 세팅했습니다. 그리고 서버 다운으로 인한 유실확률을 낮추기 위함입니다.
Queue Size는 의도했던대로
배치 사이즈(1,000건) 범위 내에서 잘 동작.
Latency - 로그를 큐에 넣는 지연시간

초반에는 큐에 한번에 많은 로그를 넣느라 지연시간이 높았으나 점차 줄어드는 양상을 확인할 수 있었습니다.
Latency - Batch Insert를 하는데 걸리는 시간
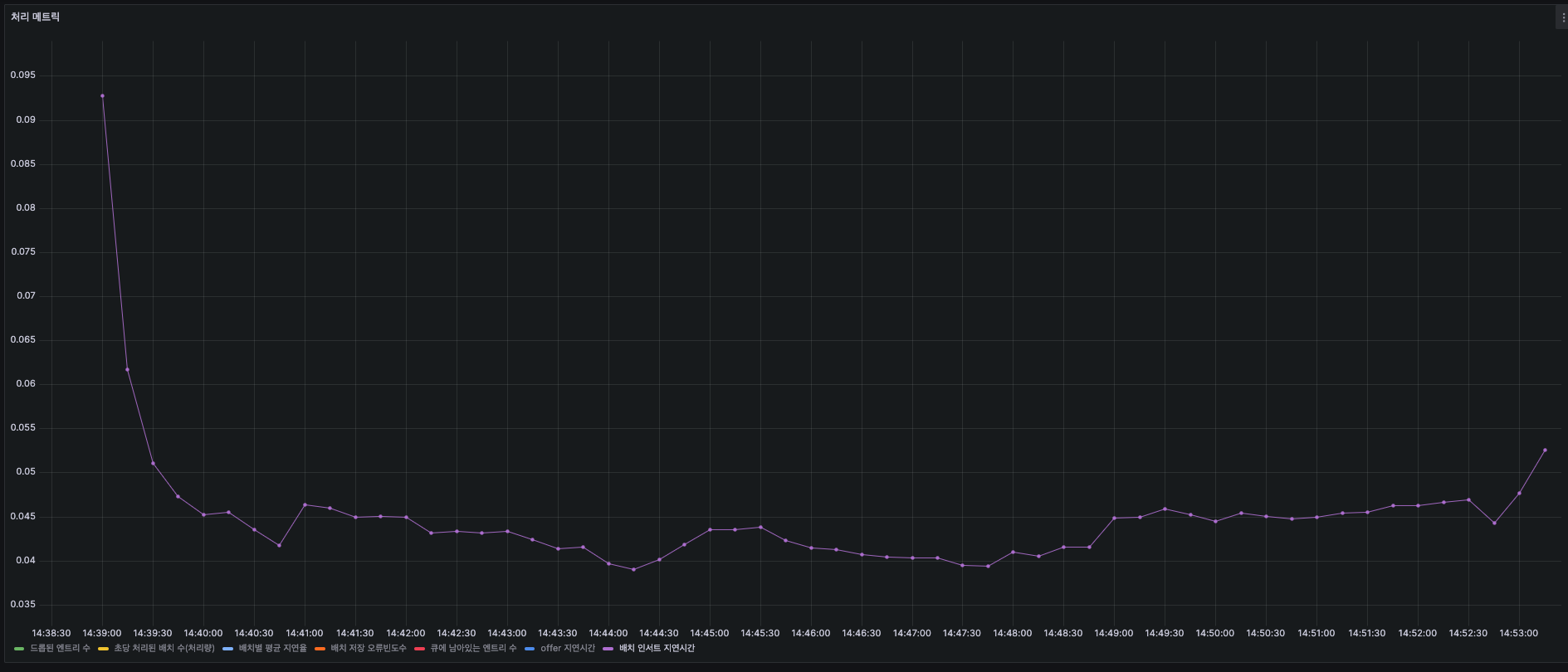
로그를 큐에 넣는데 걸리는 시간처럼 초반에 초기화를 하는데 있어서 시간을 많이 잡아먹고, 그 다음부턴 0.04~0.045 부근을 횡보합니다.
결론: 실무에서 이 구조를 선택한 이유
1. 외부 인프라가 없는 환경에서도 작동
- Kafka, Redis 없이도 순수 Java + Spring + JDBC로만 구현
- 폐쇄망(군·금융·국가기관 등)에서도 바로 적용 가능
2. 멀티스레드 환경에서도 안정적으로 동작
- BlockingQueue + ThreadPoolExecutor 구조로 동시성 처리 보장
- 유실 없이 초당 400~600건 이상 로그 처리 성능 검증
3. 운영 종료 시 flush 보장
- shutdown hook, 스케줄 기반 flush, 배치 처리 조합으로
로그 유실 없이 graceful shutdown 지원
4. JDBC batch insert 기반의 고성능
- JPA saveAll() 대신 JdbcTemplate.batchUpdate() 사용
→ 평균 메모리 사용량 2.5배 이상 절감
5. 운영에 필요한 모니터링 및 장애 대응 전략 포함
- Prometheus 지표 수집
- flush coverage 확인용 강제 장애 테스트 포함
- JSON diff, 파일 fallback 등 확장성 고려
결국, 이 구조는 "최고"는 아니지만 "현실적으로 가장 쓸만한 솔루션"
제약 조건이 명확한 환경에서
신뢰성과 운영성을 모두 확보하는 가장 실용적인 선택지였으며,
확장 가능한 구조로 설계되어 추후 고성능 요구사항도 수용 가능합니다.
Kafka 없이도 이 정도까지 가능하다는 것을
실제 실험과 수치로 검증해보고 싶었습니다.
'개발 > 대규모' 카테고리의 다른 글
| [이벤트소싱] SAGA Orchestration 패턴 + 트랜잭션 아웃박스 패턴 (0) | 2025.03.13 |
|---|---|
| [이벤트소싱] 이벤트(Event) VS 커맨드(Command) (0) | 2025.03.13 |

